
Petite note : cet article est moins technique que d’habitude. J’avais juste envie de raconter, à cœur ouvert, le développement de l’outil sur lequel je bosse, et surtout mon ressenti tout au long du dev.
Le constat : trois ans de SAST
Ça va faire plus de trois ans que je fais du DevSecOps. Dans ce métier, je manipule pas mal de SAST, et globalement je les trouve un peu nuls. Ils sortent les vulns les plus évidentes, oui, mais dès que ça devient un peu tordu, c’est vraiment pas dingue.
En sortie d’école je voulais faire du pentest (super original, je sais), alors je passais aussi pas mal de box sur HTB. C’est resté dans un coin de ma tête.
Mon premier vrai taf : l’audit de code
Ma première mission, c’était dans une ESN, en “DevSecOps as a service”. En gros, les clients venaient nous voir pour deux choses : intégrer des outils DevSecOps (SAST, SCA, DAST) dans leurs CI/CD, et parfois pour de l’audit de code.
Quand l’équipe m’a onboardé sur les audits, on m’a expliqué la méthodo et les outils. Le déroulé était toujours le même : on lançait un SAST, on triait ses résultats, et ensuite on partait sur de l’analyse manuelle.
Pour la partie manuelle, on se baladait dans le code sous VSCode. L’objectif : identifier les sources et les sinks, et vérifier qu’une source n’atteigne jamais un sink sans que la donnée ait été nettoyée au passage. Le grand classique du suivi de teinte.
Le tooling : VSCode et deux extensions qui sauvent la vie
Je ne vais pas vous faire l’affront d’expliquer ce qu’est VSCode. Par contre, au fil des audits, je me suis mis à chercher des extensions pour améliorer la qualité de vie pendant la revue.
Première trouvaille : weAudit de Trail of Bits (leur article de blog vaut le détour). L’idée est simple et géniale : prendre ses notes et suivre ses findings directement dans l’éditeur, au lieu de jongler avec un Google Doc à côté. On surligne une région de code pour la marquer comme finding (avec titre, sévérité, description, scénario d’exploit), on coche les fichiers comme audités pour suivre l’avancement, et on partage tout ça avec ses co-auditeurs via un simple fichier dans le .vscode du projet. Pas de cloud, pas de serveur : un fichier qui voyage avec le repo.
Ensuite, Inline Bookmarks de tintinweb. Là, le principe c’est de poser des marque-pages colorés via des tags en commentaire directement dans le code : @audit, @audit-info, @audit-ok, @audit-issue… Chaque tag prend une couleur, s’affiche dans la marge, et tous les marque-pages se retrouvent dans une arborescence sur le côté. Comme ce sont de simples commentaires, ils restent dans le fichier et se partagent avec le reste. Parfait pour marquer tes sources et tes sinks sans rien perdre.
La frustration : pourquoi les pentesters ont droit aux beaux jouets ?
Quand j’ai commencé l’audit de code, je faisais beaucoup de veille et de formation sur le pentest web en parallèle. Et le pentest, c’est une quantité de tools super cool et hyper bien finis : Burp Suite, Caido, BloodHound, nuclei, etc.
Utiliser des outils carrés pour le pentest et, à côté, faire de l’audit de code sur VSCode (qui est cool, mais clairement pas taillé pour les grosses applis), ça a fini par me créer une vraie frustration. Pourquoi les pentesters auraient le droit aux beaux jouets et pas nous ?

Petit détour par les SAST (parce qu’il faut bien)
Jusqu’ici je n’ai pas trop parlé des SAST, et c’est volontaire. Perso, je les trouve plutôt cool et très utiles tôt dans le cycle de vie logiciel. Un SAST, pour rappel, c’est de l’analyse statique : il lit ton code sans l’exécuter et cherche des patterns de vulns.
Le souci, c’est que l’audit de code arrive souvent tard dans la SDLC. Et à ce moment-là, même avec une belle interface, les résultats du SAST sont assez faibles. Sans parler du nombre ahurissant de faux positifs selon le type de projet. Un faux positif, c’est l’outil qui crie au loup sur du code en fait sain : tu perds un temps fou à trier pour rien.
Pourtant, les SAST reposent sur des technos vraiment chouettes. En creusant un peu, je suis tombé sur les règles custom.
Les règles custom : Semgrep, CodeQL, Joern
Semgrep
Semgrep permet d’écrire ses propres règles de détection en YAML, puis de relancer un scan avec. Et franchement, l’écriture de règles est simple et super bien documentée, ce qui est loin d’être le cas partout.
Tu as plusieurs façons de matcher : des pattern pour cibler une expression, et surtout un mode taint avec pattern-sources, pattern-sinks et pattern-sanitizers pour suivre le flux de données et lever un finding quand une source atteint un sink sans être assainie.
C’est cool, mais il faut écrire une règle, relancer un scan, vérifier, ajuster, relancer… et trouver le bon curseur entre vrai et faux positif. Plus ta règle est générique, plus tu génères de faux positifs et plus tu passes de temps à trier. Logique, mais pénible.
CodeQL
En creusant encore, on tombe sur CodeQL, développé par GitHub. CodeQL te laisse “parler” à ton code comme si tu faisais des requêtes SQL sur une base de données : il transforme le code en base interrogeable et tu écris des requêtes en QL pour suivre les flux et la teinte, y compris entre fonctions.
Quand j’ai découvert ça, j’avais des étoiles dans les yeux. C’est exactement le genre d’outil que je cherchais. Sauf que la licence est contraignante : c’est gratuit sur du code open source et pour la recherche académique, mais dès que tu l’utilises sur du code privé ou proprio (typiquement le code d’un client en presta), il te faut une licence GitHub Advanced Security. Les requêtes, elles, sont sous licence MIT ; c’est le moteur CLI qui porte les conditions propriétaires de GitHub, et “open source” y signifie strictement licence approuvée OSI : le code d’un client ne rentre jamais dans la case. Pour un auditeur en presta, c’est rédhibitoire.
Joern
Puis je suis tombé sur Joern. Open source, sous licence Apache 2.0, donc libre même en usage commercial. Lui aussi transforme le code en graphe interrogeable (un Code Property Graph, on y revient), et tu le questionnes via un langage de requête en Scala dans un shell interactif. Le concept de CPG sort d’un papier IEEE S&P 2014 de Fabian Yamaguchi et ses co-auteurs, qui s’en servaient pour dénicher 18 vulns inconnues dans le noyau Linux. Yamaguchi est aussi l’auteur originel de Joern : l’outil est quasiment l’implémentation de référence du papier.
La comparaison avec CodeQL tient en une phrase : CodeQL est plus poli et plus précis, mais bloqué par sa licence en commercial ; Joern est libre, mais plus rêche.
Et “rêche” est le bon mot. Le problème de Joern, c’est une courbe d’apprentissage assez lourde, et surtout, à ma connaissance, aucun moyen de sauvegarder ses findings avec le code à côté. Tu trouves un truc, et tu te débrouilles pour le noter ailleurs.
C’est là que je me suis dit : “et si je faisais mon propre outil ?”
“Et si je faisais le mien ?”
Au départ, je voulais faire mon propre SAST, un qui me donnerait enfin de vrais résultats. C’est là que j’ai compris que c’était une galère pas possible.
L’idée que j’avais, c’était d’avoir l’équivalent de BloodHound, mais pour l’audit de code. BloodHound, pour ceux qui ne connaissent pas, modélise les relations d’un Active Directory sous forme de graphe et te laisse trouver des chemins d’attaque (le fameux plus court chemin vers Domain Admin) avec des requêtes. Or une vuln, au fond, c’est aussi un chemin : source vers propagation vers sink. Exactement le même problème de traversée de graphe.
Donc : représenter une codebase sous forme de graphe, et lancer des règles custom ou des presets pour vérifier s’il y a une vuln. En gros, un Joern avec une belle UI/UX.

Alors ne me demandez pas pourquoi, mais au départ je voulais coder mon propre algo de CPG. J’étais parti sur tree-sitter comme brique de base, ce qui me donnait un AST très propre. L’avantage de tree-sitter, c’est une bonne couverture des langages dès le départ et un outil mature.
Un AST (Abstract Syntax Tree), c’est la structure syntaxique de ton code : la grammaire, rien de plus. Un CPG (Code Property Graph), c’est un AST PLUS le graphe de flot de contrôle PLUS le graphe de dépendances de données, le tout fusionné dans un seul graphe. C’est cette fusion qui rend possible les requêtes de teinte. Et entre un AST et un CPG, il y a un monde : il faut construire le flot de contrôle, le flux de données, le graphe d’appels… du boulot d’ingénierie énorme, spécifique à chaque langage. Si vous voulez creuser, j’ai écrit un article entier sur les CPG.
J’ai vite commencé à avoir des résultats complètement illisibles, parce que mon algo était nul, pour être franc.

J’étais frustré de ne pas arriver à faire ce que je voulais. J’ai donc stoppé définitivement le développement de cet outil. Il s’appelait spotted, et ce fut ma plus grosse déception. Déçu de ne pas y être arrivé, et de ne même pas avoir réussi à pondre un truc un minimum utilisable.

Le rebond
Avec le temps, j’ai continué ma veille sur ces sujets, et je suis tombé sur des articles de dingue (ou un bon ami me les envoyait, cc Adrien). Deux que je vous conseille vraiment :
- WTF is AI-native SAST ? de Parsia. Sa thèse, sans bullshit : l’AI-native SAST, c’est juste “SAST + AI”. Le SAST classique a toujours été mauvais sur certaines classes de bugs (autorisation, logique métier) parce qu’il ne saisit pas l’intention du code. L’idée : laisser l’analyse statique repérer où chercher, puis envoyer le LLM cibler ces endroits avec juste le contexte pertinent. L’IA ne remplace pas le SAST, elle s’appuie dessus.
- The Deductive Engine de pwno. Eux renversent le truc : au lieu d’utiliser le LLM comme assistant du SAST, ils en font le moteur de raisonnement lui-même. Le LLM raisonne en taint analysis comme nous le ferions intuitivement (propagation arrière, find-definition, find-reference). Résultat : une trentaine de vulns sur un binaire de routeur en une journée, dont 12 validées par des PoC fonctionnels. Le tout auto-financé, pour environ 4 dollars et 1 à 8 minutes par bug.
Lire ça, voir ce que des gens arrivent à faire, ça m’a grave remotivé. Sans parler des copains qui m’ont poussé à reprendre le dev (cc skilo, had, hexo, billy, adrien).

On repart de zéro (et en Rust, va savoir pourquoi)
J’ai décidé de repartir de zéro. Et cette fois, de me baser sur Joern : de toute façon, je n’ai ni le temps ni les compétences techniques pour re-développer un moteur du genre.
Je me suis donc focalisé sur l’intégration de Joern dans un workflow d’audit de code plus moderne. Une application web qui permet d’ingérer des codebases, de les questionner (requêtes Joern) et d’orchestrer tout ce petit monde.
Ça tombait en même temps que j’apprenais le Rust. Du coup, à mon plus grand désespoir, j’ai décidé de faire tout le backend en Rust. Help.
Après deux mois de dev, j’avais un outil un minimum viable pour mon usage perso. Le souci : côté UX c’était pas top, et côté UI c’était vraiment horrible. Comme je m’étais pas mal aidé de Claude, l’UI ressemblait à la plupart des outils vibe-codés. Et comme j’aime bien le design, ça m’a vraiment contrarié.

Voici quelques exemples de la première UI :
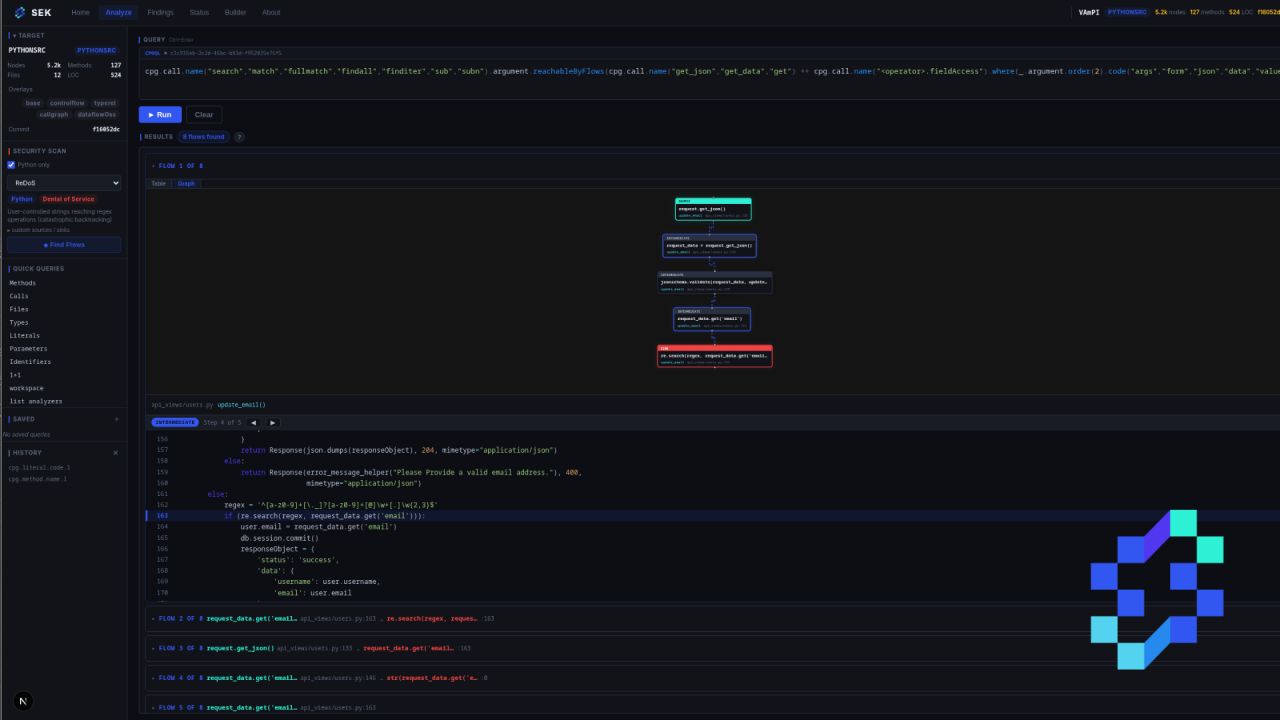
Les premières CVE!
Le temps a passé, et j’ai réussi à trouver mes premières CVE grâce à cet outil. Là, c’était le moment de commencer à le présenter à mes collègues.
Franchement, j’ai été surpris par l’accueil. La plupart ont trouvé l’outil vraiment cool et ont vu sa vraie plus-value. Ça m’a fait super plaisir. Savoir que d’autres partagent mon constat et que ce que j’ai dev peut être utile, j’ai trouvé ça vraiment chouette. J’ai pas mal d’outils sur mon GitHub, mais la plupart sont des petits projets pas vraiment utilisés.

sek
Après une petite pause bug bounty, j’ai repris le dev sérieux du tool. D’ailleurs il a un petit nom : sek.
Pour bien reprendre, je me suis fixé un objectif : définir la direction artistique (logo, palette de couleurs, police). Je comprends que certains trouvent ça relou, mais perso c’est vraiment ma partie préférée, même si je suis loin d’être un pro du domaine. Voici la charte définie :

Ensuite, refonte complète de l’UI. J’ai commencé par un prototype Figma pour avoir une vue claire, et franchement ça m’a énormément aidé.
Fin mai : si proche, si loin
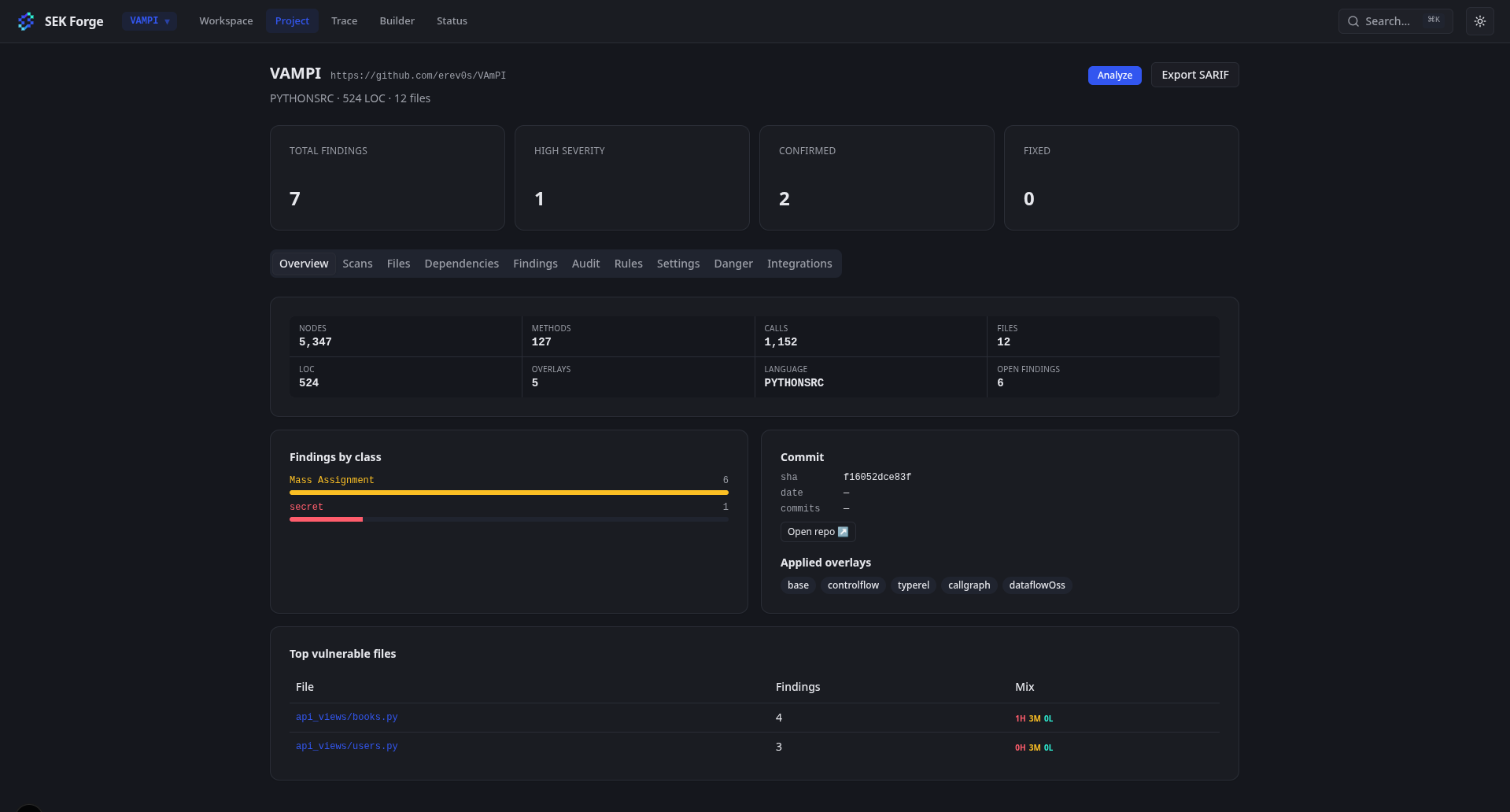
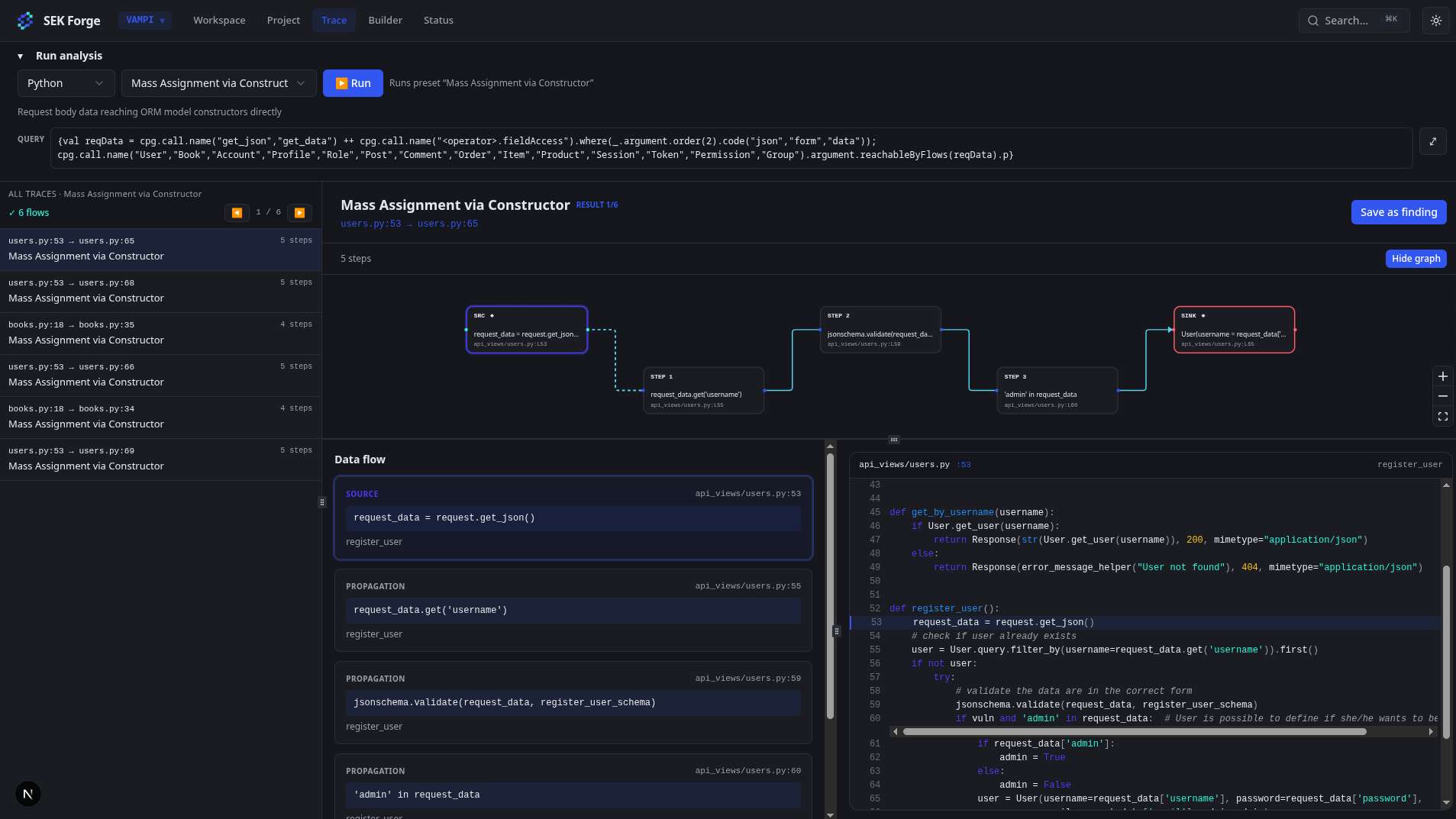
Et nous voilà fin mai. Je commence à avoir un outil presque viable, et ça fait vraiment plaisir de se sentir si près du but. Mais plus j’avance, plus je me rends compte que je ne suis pas si proche de la version finale que je veux.

Voici quelques images du tool, sans trop spoiler :
La suite
Voilà. J’espère que ce format vous plaira aussi. Je continuerai à écrire des articles sur mes péripéties avec cet outil.